
Game architecture, like all software architecture, tends to be neglected or forgotten as a project goes on. Scalable, enjoyable, production codebases are so rare they're almost mythical.
It doesn't have to be this way: just because video game development is difficult doesn't mean it has to be painful. You can still achieve a robust software architecture that scales with your game — even as you rework core systems and make sweeping refactors. Since architecture is based on expert opinions and developer experiences, we'll borrow from the wisdom of other software architectures to create a game architecture that prioritizes an enjoyable developer experience.
Over the last few years, I've been making and maintaining over a dozen open source packages for Godot and C#. While leveraging these packages and the opinionated architecture described in this article, I was able to build a 3D platformer demo in just a month or two of spare time. If you're willing to stick around, I'd love to share the methodology, the rationale, and even the demo itself with you.
In the demo, your goal is to collect all the coins hidden in the 3D world. Go ahead and take a quick look at the demo's code on GitHub: if you like the way the code is written, you'll like this article. If you don't, you should write a rebuttal. Either way, I look forward to hearing from you.
chickensoft-games/
GameDemo

Most of the assets used in the demo are free assets created by GDQuest — please check them out and support their efforts!
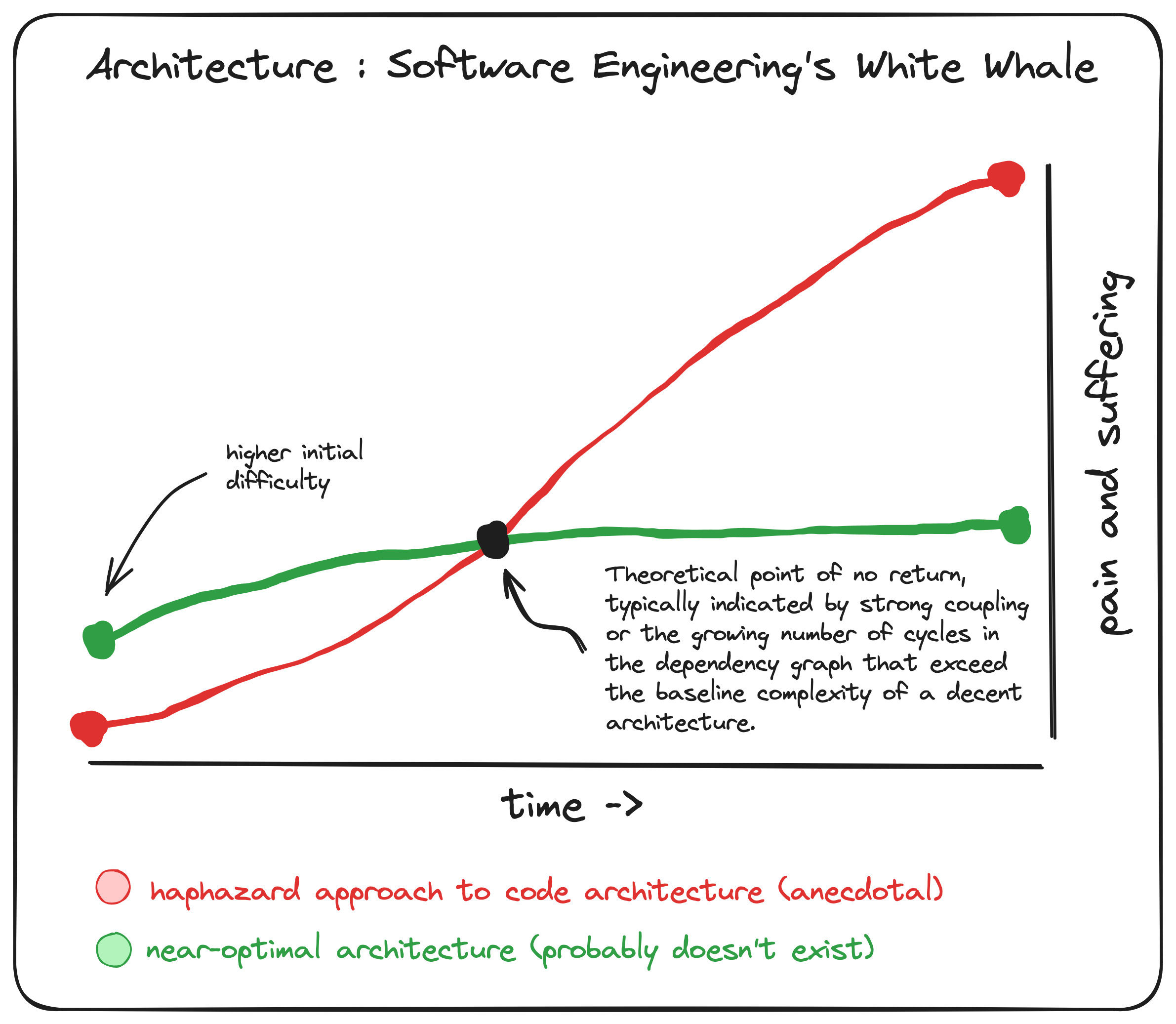
Why am I tackling something as subjective and nebulous as architecture? Because, deep down inside, I believe most of us don't want to bother with architecture. We just want to make our game and have a good time doing it. Unfortunately, if you just start writing code without a second thought, you'll often find that the further you get, the harder it gets.
💡 What Is Software Architecture?
You already know, but we'll define it anyways for the sake of completeness.
A software architecture is a set of rules and practices designed around the developers' goals for their team's code.
Whether or not those practices actually accomplish those goals is another matter entirely.
I believe a good architecture is opinionated, based on learnings from past projects which met the same (or similar) goals, and plays nicely with the development tools for your particular stack: i.e., a good architecture should provide structure, be based on experience, and be practical to implement.
If there's two equally good ways to do something, a good architecture will pick one as the recommended approach. Good architectures embrace collectivism, not individualism. Each feature or component should be implemented similarly to the other features and components. Increasing code-similarity allows developers to ramp up quickly, switch between features with relative ease, and reduces the number of complex details they have to remember.
Below, I've listed some common, high-level goals that a good architecture might be designed around. These goals range from overall organizational practices to annoying details about where files should be placed and how code should be formatted and linted.
- Organization: Where do I put code and related assets when adding a new feature?
- Development: How do I know what code to write to accomplish a feature?
- Testing: How do I write tests for my feature?
- Structure: How do I get the dependencies my features need?
- Consistency: How do I keep my code formatted? (Yes, this is important. If you don't have automatic style enforcement, you can run into problems where your IDE's language server is trying to apply auto-fixes that make your life hard with the style of coding you've chosen.)
- Flexibility: What happens when I need to refactor something? An optimal architecture would allow us to overhaul a feature without breaking the other features, enabling us to iterate faster and keep our code flexible.
While the architecture can't hold your hand and give you line-by-line coding instructions (that's the job of the senior developers on your team), it should, at least, give you a good idea of where to start when you first grab that ticket off the backlog.
A good architecture should help prevent writer's, er, coder's block when you first start on a new feature. It should take the guesswork out of what should be mundane procedures (like scaffolding out a new view, its state management, and its tests) and turn it into something you can do in your sleep (or automate with some snippets).
To achieve the lofty goals above, we'll create specific, concrete requirements for our architecture that serves our noble goals. Our ideal architecture should…
- Define abstraction layers to organize code modules.
- Provide an organization system for the files and assets in the codebase.
- Allow each "unit" of code to be tested in isolation.
To meet these goals, we'll draw inspiration from a number of existing patterns and architectures, casually incorporating whatever we like.
🍰 Abstraction Layers
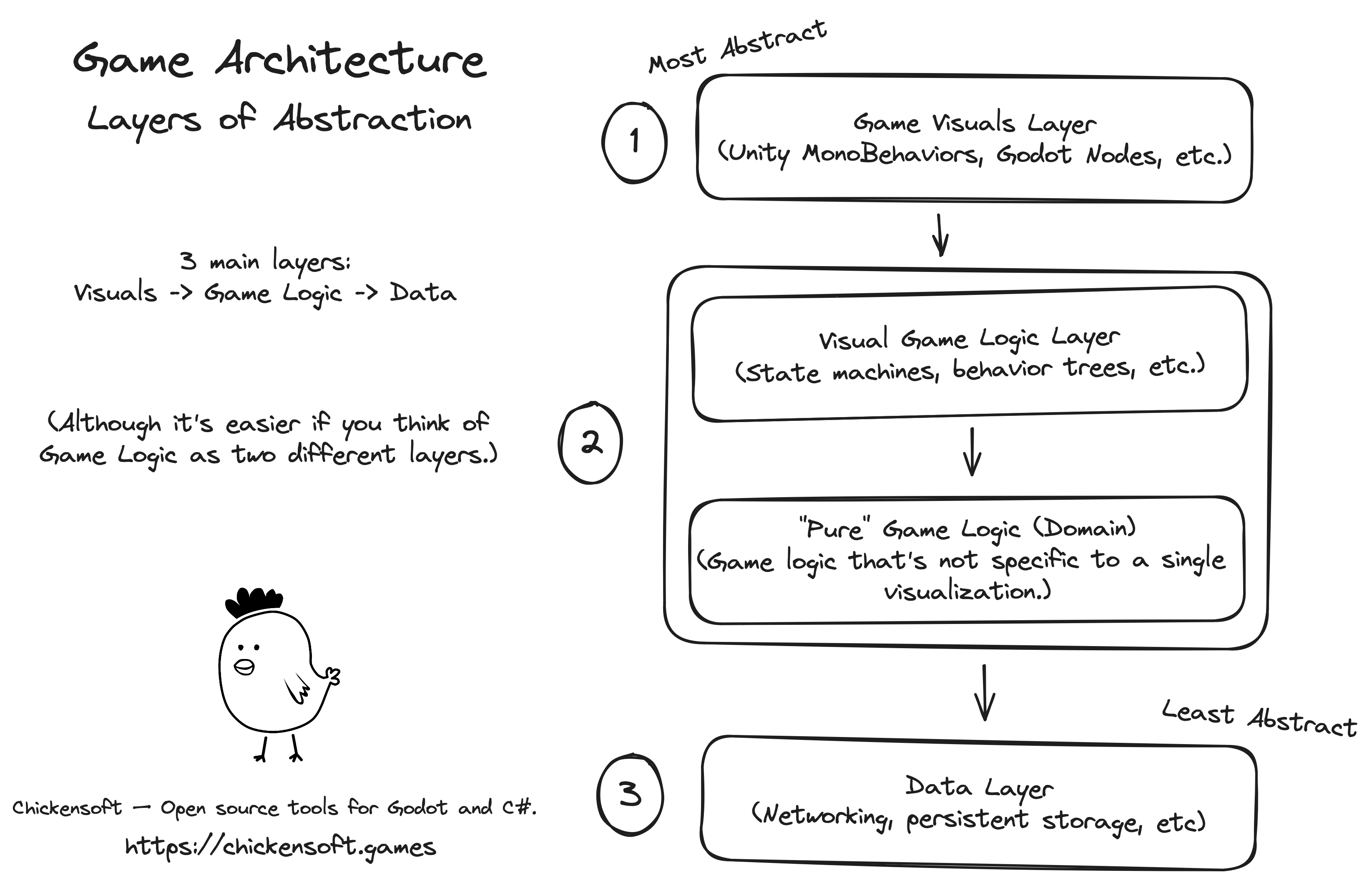
Our ideal architecture should provide an opinion about the overall structure of our game. In a typical visual application, you might have the view layer, business logic / domain layer, and the data layer.
For games, we can make our own, similar layers. Each layer will correspond to a type of object in our codebase.
- Visual Layer — Scripted game engine components. A Unity
MonoBehaviorattached to a game object, a GodotNodescript class, etc. - GameLogic Layer — the meat and potatoes of your game, itself broken into two "sublayers":
- Visual Game Logic Layer — state machines, behavior trees, or other stateful mechanisms that drive a single game engine component's state.
- Pure Game Logic Layer — repository classes that perform game logic that's not specific to any single visual component.
- Data Layer — Various client classes for "lower level" interactions, such as networking and persistent storage.
Together, these 3 abstraction layers allow us to look at our game critically. Most pieces of code should fall into one of those layers nicely.
Differentiating game logic into visual game logic and pure game logic is an idea reminiscent of the way clean architecture distinguishes between "enterprise-wide business rules" and "application specific business rules."
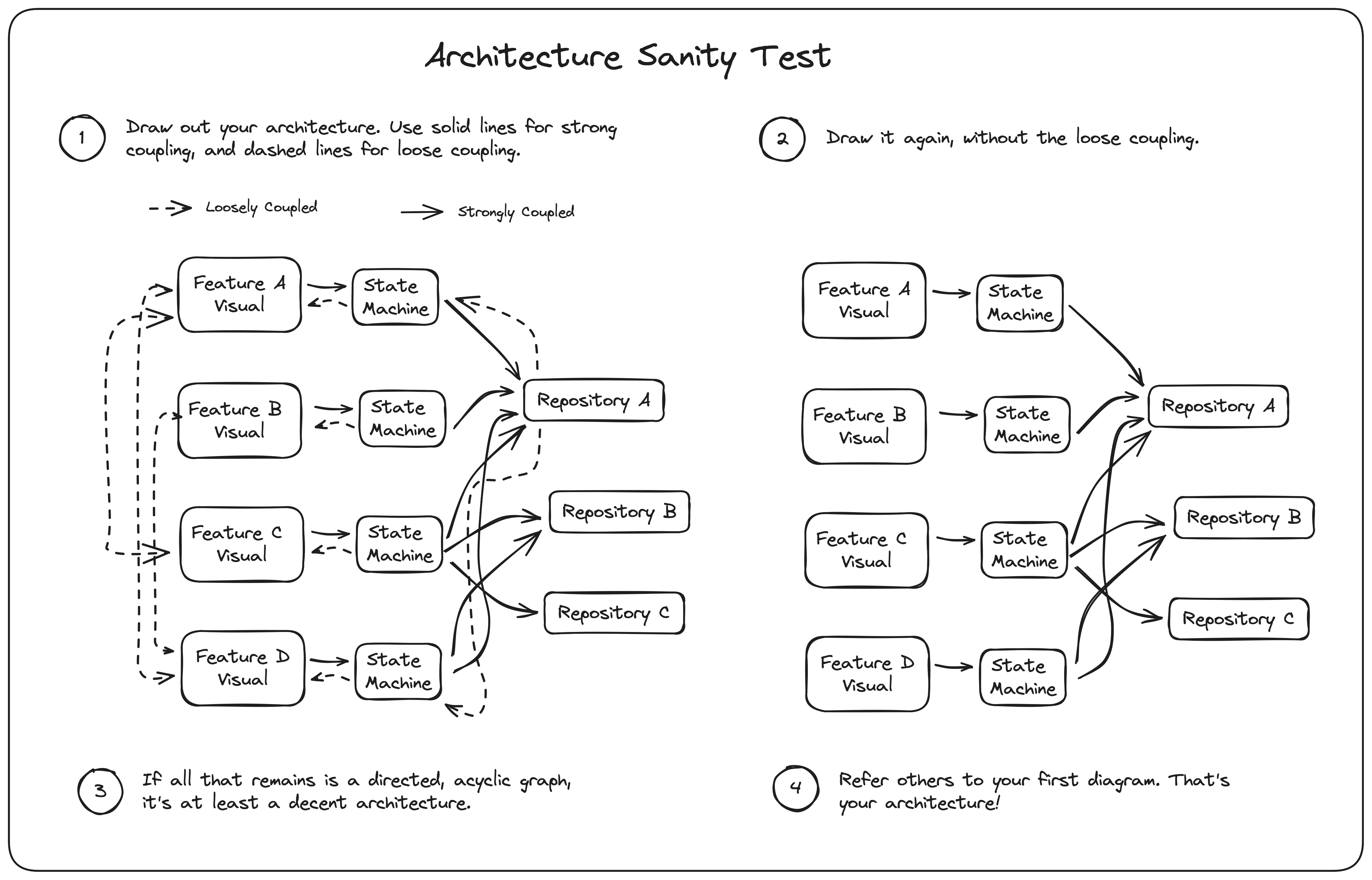
We'll also introduce an additional stipulation into our architecture: objects in one layer can only be strongly coupled with objects in the layer directly below them. You might recognize this rule from the strict form of layered architecture.
Restricting objects to only interacting with objects in the layer directly beneath them prevents sibling dependencies in the same layer (strong coupling), as well as "skipping" layers, which would indicate a design oversight.
🎭 Visual Layer
Visual components drive the things we see in the game engine. They come in many flavors, but tend to be pretty similar across game engines. In Unity, you'll find MonoBehavior components that are applied to GameObjects. In Godot, we subclass a Godot Node and attach the script to a scene node. Both of these systems allow us to represent visual components within the engine.

Most game developers will reiterate the importance of separating your visual logic from your game logic, citing the single responsibility principle — so, how do you do that exactly?
Mechanisms like state machines and behavior trees are commonly used to separate the "state" of something from the code that visualizes it. For example, a visual script can create a state machine and provide a reference to itself to the state machine, allowing the state machine to "drive" the visual object as it changes between states. The visual script can likewise hang onto a reference to its state machine, forwarding relevant input events to it, giving the state machine a chance to drive it whenever something happens.
An optimal architecture would probably eliminate conditional branching from visual game component scripts altogether, performing all logic in the component's state machine or other state mechanism.
Real life isn't always so pretty, though: for performance reasons, it's often advantageous to have a few checks in the visual component itself to decide if it's even worth passing an event to the state machine. If you don't, garbage collected languages like C# can generate a lot of unnecessary memory pressure, depending on how carefully you handle input queuing and memory allocation.
Below is a minimum example of a visual node script. For the sake of example, it is completely stateless. The only event that can happen — the main menu button being pressed — is forwarded via the use of a signal, allowing a stateful ancestor to manipulate this node.
[Meta(typeof(IAutoNode))]
public partial class WinMenu : Control, IWinMenu {
public override void _Notification(int what) => this.Notify(what);
#region Nodes
[Node]
public IButton MainMenuButton { get; set; } = default!;
#endregion Nodes
#region Signals
[Signal]
public delegate void MainMenuEventHandler();
#endregion Signals
public void OnReady() => MainMenuButton.Pressed += OnMainMenuPressed;
public void OnExitTree() => MainMenuButton.Pressed -= OnMainMenuPressed;
public void OnMainMenuPressed() => EmitSignal(SignalName.MainMenu);
}
You'll often find that many nodes can be stateless, simply signaling when something happens. Stripping as much logic out of the visual layer is beneficial because it allows stateful, parent nodes to manipulate the simpler, stateless nodes. For comparison, Google's cross platform app framework Flutter specifically forces you to distinguish between a StatefulWidget and a StatelessWidget. This same distinction applies to Godot, since they both share a visual, tree-based composition structure.
We'll be making extensive use of the Introspection source generator, which lets us inject code into our node classes via mixins.
In the example above, the IAutoNode mixin enables the WinMenu class to connect the MainMenuButton property to its corresponding node with the same unique identifier, %MainMenuButton in the scene. Little tricks like that help save us a ton of error-prone typing.
The IAutoNode mixin comes from AutoInject, which provides a number of utilities in addition to dependency injection.
🤖 GameLogic Layer
Game logic simply refers to code that manipulates the game and its mechanics, without having to directly worry about other concerns like how the game is visualized, networked, or persisted.
In our architecture, we differentiate between two kinds of game logic. Let's look at each one.
🖼 Visual Game Logic Layer
As mentioned, visual game logic is just code that's specific to a single visual component (state machines, behavior trees, or other stateful mechanisms that belong to a specific visual component).
For visuals that do anything more than just appearing in game, they should probably have a reference to a behavior tree, state machine, statechart, or other such stateful mechanism that represents their state-of-being.
Stateful mechanisms can have be loosely coupled to their owning components via an interface, enabling them to "drive" their visual components by calling methods on them or producing outputs that the visual game component binds to.
The visual component's job is to shut up and look pretty. The dumber it is, the better. An ideal visual component will just forward all inputs to its underlying state machine (or whatever it's using).
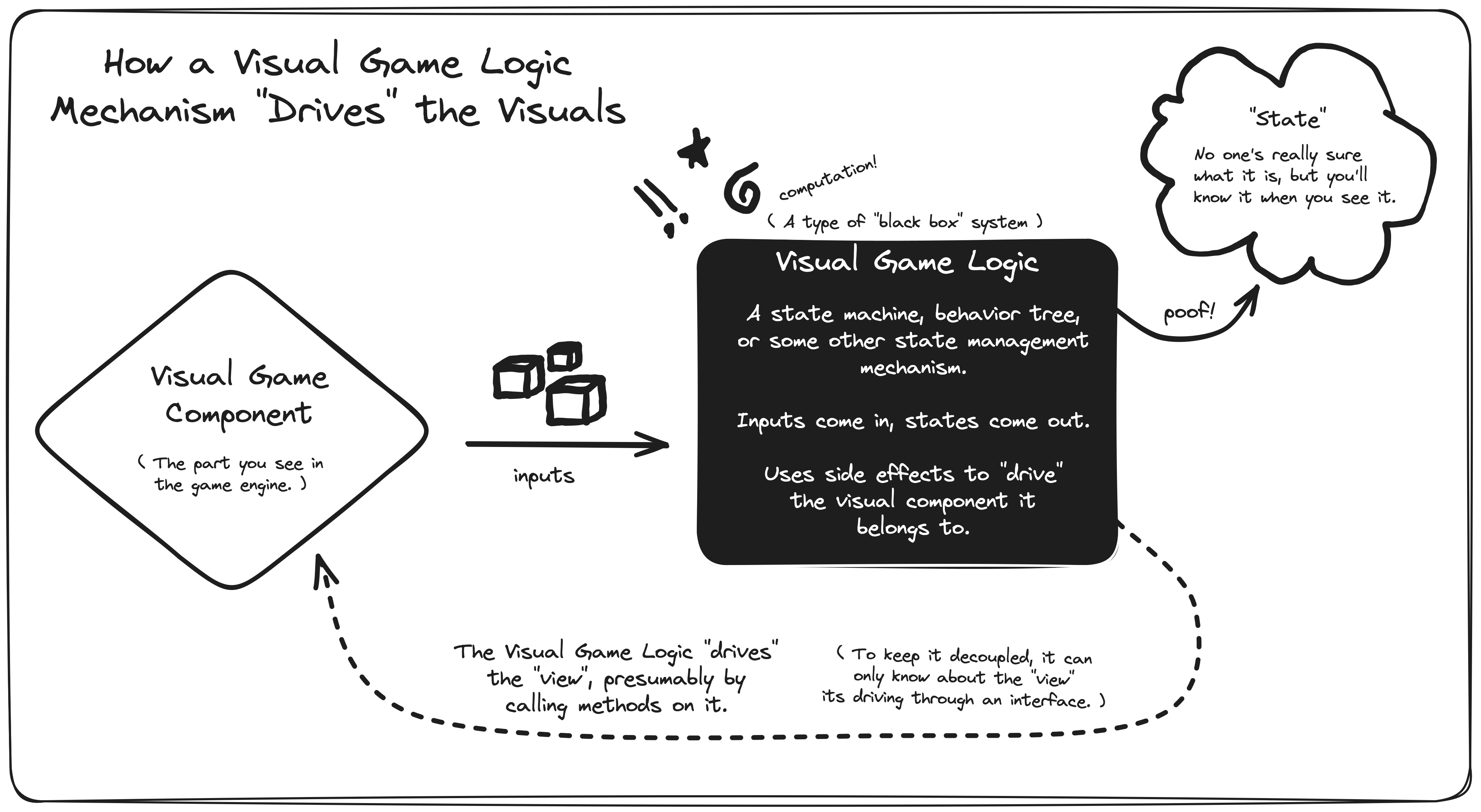
State Management In Practice
For some of the more complex visual components in your game, a simple state machine would get out of hand quickly. Most likely, you'll end up using a statechart, a type of hierarchical state machine that can help avoid the pitfalls of ordinary state machines.
Fortunately, I've already created an ergonomic, hierarchical state machine implementation called LogicBlocks that allows you to write your states the way you write ordinary C# classes records. In the game demo, LogicBlocks easily handled the menu transition logic, overall pause mode, player state machine, and every other stateful component.
I'd recommend at least considering using LogicBlocks, for the following reasons:
- Includes a picture generator that reads your code and helps you visualize it as a UML state diagram.
- Easily testable (abstracts inputs and outputs).
- No need to define transition tables. It operates more like a Moore machine, which is a lot more ergonomic than the typical transition-based approach.
- Correctly implements state entrance and exit callbacks for nested states.
- Correctly queues and processes inputs.
- Provides states with a blackboard — a shared data store.
- Includes an ergonomic binding system that allows you to easily synchronize the visual component with its state.
- LogicBlocks can add input to themselves, allowing them to initiate subsequent state changes.
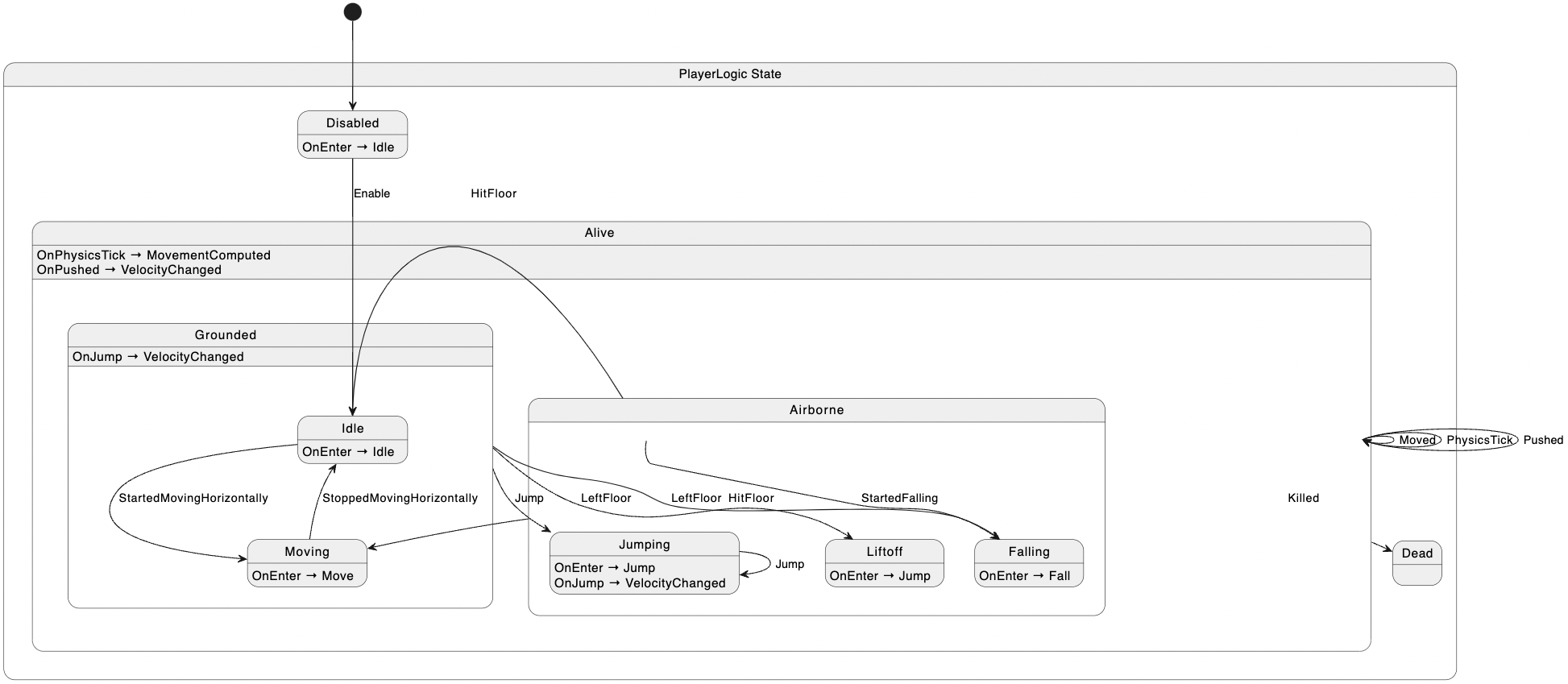
Below, here's the InGameUILogic state machine from the game demo. It's an incredibly simple state machine — it only has one state that subscribes to the AppRepository (see next section for details) and produces outputs whenever the number of coins changes.
public partial class InGameUILogic {
public record State : StateLogic, IState {
public State(IContext context) : base(context) {
var appRepo = context.Get<IAppRepo>();
OnEnter<State>((previous) => {
appRepo.NumCoinsCollected.Sync += OnNumCoinsCollected;
appRepo.NumCoinsAtStart.Sync += OnNumCoinsAtStart;
});
OnExit<State>((next) => {
appRepo.NumCoinsCollected.Sync -= OnNumCoinsCollected;
appRepo.NumCoinsAtStart.Sync -= OnNumCoinsAtStart;
});
}
public void OnNumCoinsCollected(int numCoinsCollected) {
Context.Output(new Output.NumCoinsCollectedChanged(numCoinsCollected));
}
public void OnNumCoinsAtStart(int numCoinsAtStart) {
Context.Output(new Output.NumCoinsAtStartChanged(numCoinsAtStart));
}
}
}
Meanwhile, the actual Godot Node for the InGameUI binds to the state machine's outputs, updating the UI whenever the number of coins changes.
[Meta(typeof(IAutoNode))]
public partial class InGameUI : Control, IInGameUI {
// ...
public void OnResolved() {
InGameUIBinding = InGameUILogic.Bind();
InGameUIBinding
.Handle<InGameUILogic.Output.NumCoinsCollectedChanged>(
(output) => SetCoinsLabel(
output.NumCoinsCollected, AppRepo.NumCoinsAtStart.Value
)
)
.Handle<InGameUILogic.Output.NumCoinsAtStartChanged>(
(output) => SetCoinsLabel(
AppRepo.NumCoinsCollected.Value, output.NumCoinsAtStart
)
);
InGameUILogic.Start();
}
public void SetCoinsLabel(int coins, int totalCoins) {
CoinsLabel.Text = $"{coins}/{totalCoins}";
}
// ...
}
🎰 Pure Game Logic Layer
"Pure" game logic encompasses the "domain" of your game. Components in the pure game logic layer are typically repositories, which are usually just plain-old C# classes. Repositories are responsible for implementing the rules that compromise your game's domain.
The Domain of Chess
In chess, the rook can capture any piece in its path if doing so would not put the king in check. The rook must also stop at the location where the capture occurs. The concept of "capturing" is a rule specific to chess, and thereby exists within the "domain" of chess.
Because capturing involves more than just a single chess piece, it can't be implemented cleanly in the visual game logic layer. Instead, the state machine for a rook might realize it's being directed to capture a piece, and then call a repository method to attempt the capture. If the rook is allowed to capture the piece, the repository will perform the capture, firing an event that the newly captured piece would already be subscribed to. The captured piece will remove itself from the board, and the repository can return a success indicator to the rook's state machine.
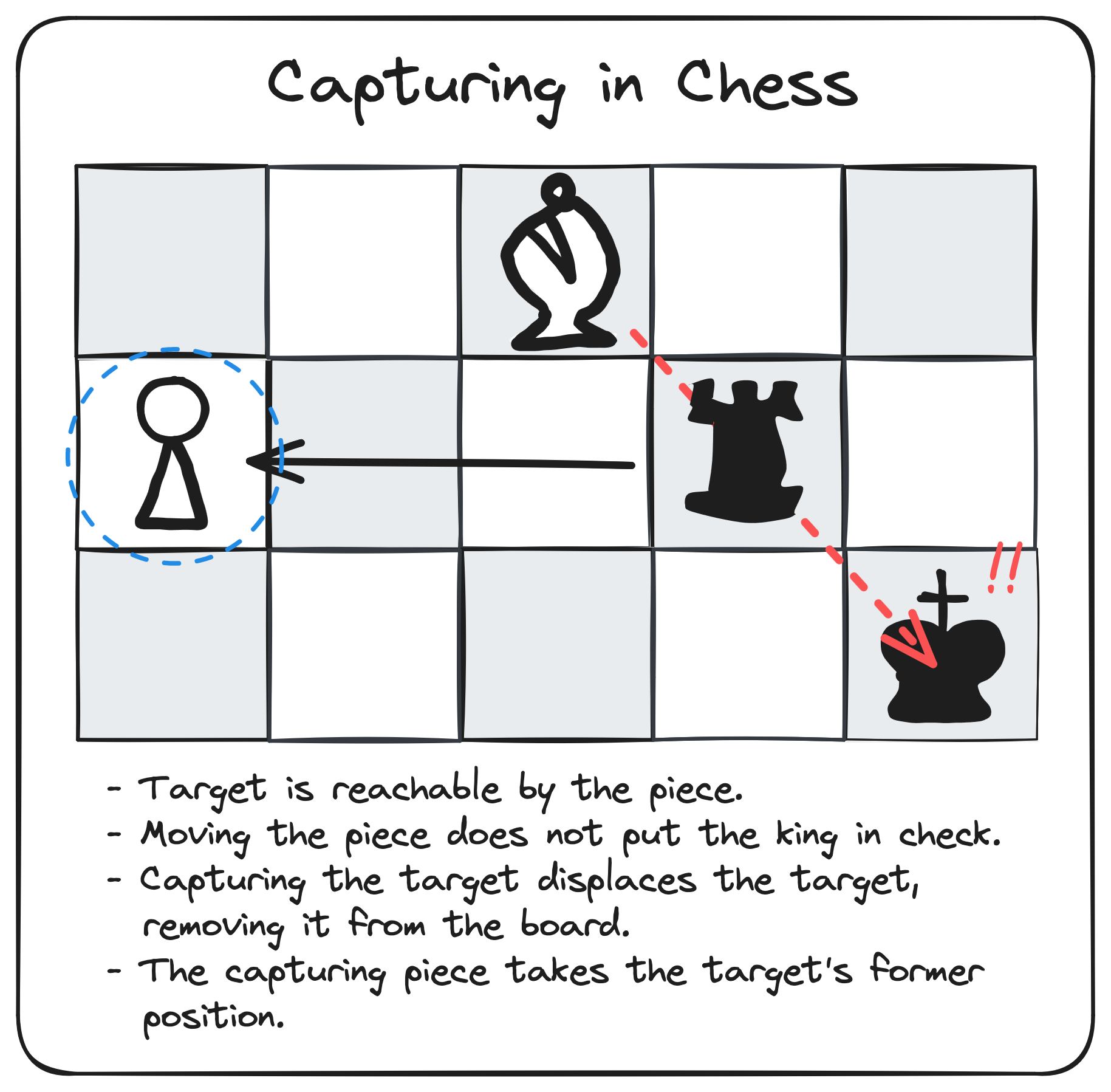
Making Repositories
In the game demo, we have an AppRepository that allows us to handle the game logic for the entire app. Since collecting coins affects more than just a single visual component and is responsible for how you win the game, we handle coin collection inside the AppRepository.
/// <summary>
/// Pure application game logic repository — shared between view-specific logic
/// blocks.
/// </summary>
public class AppRepo : IAppRepo {
// ...
public void StartCoinCollection(ICoin coin) {
_coinsBeingCollected++;
_numCoinsCollected.OnNext(_numCoinsCollected.Value + 1);
CoinCollected?.Invoke();
}
public void OnFinishCoinCollection(ICoin coin) {
_coinsBeingCollected--;
if (
_coinsBeingCollected == 0 &&
_numCoinsCollected.Value >= _numCoinsAtStart.Value
) {
OnGameEnded(GameOverReason.PlayerWon);
}
}
// ...
}
We've omitted quite a lot for the sake of brevity, but you probably get the idea: whenever a coin detects a collision with the player, it sends an event to its state machine, which starts the coin collection animation and tells the AppRepository that a coin is being collected. When the animation finishes, it tells the AppRepository that it's finished being collected.
The AppRepository tracks the number of coins that were collected and then fires an event to end the game. Other state machines on other visual components are subscribed to the game-over event, handling cleanup or transitioning to other screens, as needed.
How Data Flows in a Game
A good state machine, behavior tree, or other state implementation should be able to subscribe to events occurring in repositories, as well as receive events and/or query data from the visual component they belong to.
You can think of data flowing down into the state from the visual component that owns it, and bubbling upward from game logic repositories that need to broadcast events.
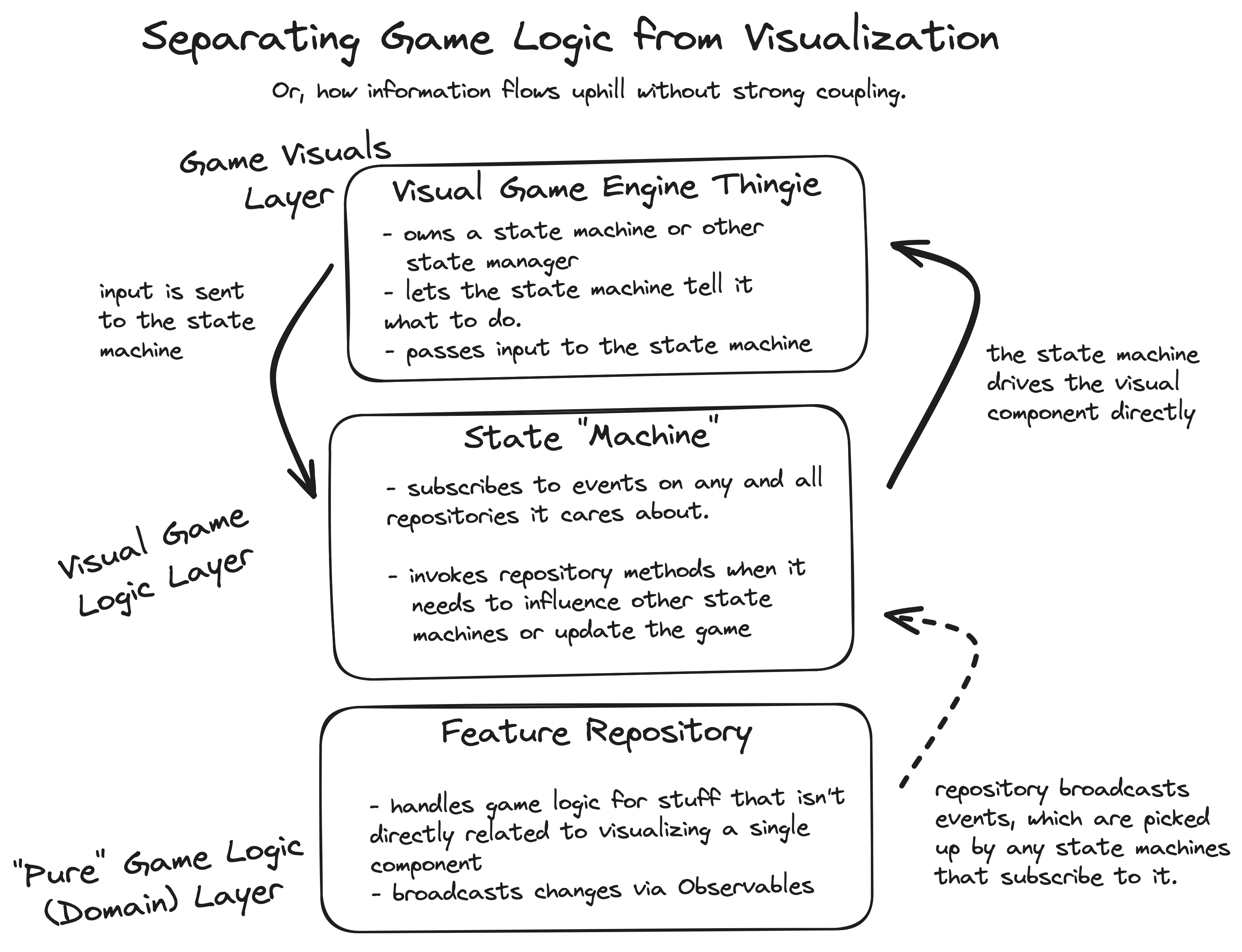
If all of this sounds familiar, it's probably because it's a reactive (as in ReactiveX, or rx) style of coding. Or maybe you've used an event bus — another type of loosely-coupled, observable system.
I tend to think of reactive-style code like glue: it's extremely powerful, messy, and gets everywhere — so use sparingly! If you've ever tried to explain multiple chained event source transformers that zip elements together to a junior programmer, you know just how tricky it is to wrap your head around. It's also tricky for yourself, 6 months in the future.
For the sake of convenience, I use a little reactive utility called AutoProp inspired by C#'s built-in events and observers. It's more or less the same API as a C# observer, but with a few tweaks to be more ergonomic.
public IAutoProp<bool> MyValue => _myValue; // expose read-only version
private readonly AutoProp<bool> _myValue = new AutoProp<bool>(false);
To keep things sane, we can create feature-specific game repositories. These repositories can be provided to any game component's state mechanism, allowing it to subscribe to the events offered by that repository. Since the visual game logic layer exists directly above the pure game logic layer, only state mechanisms will be allowed to interact with and subscribe to repositories.
💽 Data Layer
The data layer represents various data clients in your application, like your network client or file client. In many cases, the game engine itself can suffice.
Because the data layer is the lowest layer of the application, repositories in the domain layer (your pure game logic) usually invoke various methods on the data layer to send and receive what they need through various channels. Like state machines subscribing to repositories, repositories can themselves subscribe to incoming data from the data layers, invoking their own events when something relevant in the game occurs, allowing all the relevant state machines to receive updates, which in turn updates their visual components. It's turtles all the way up.
I didn't implement a game saving or loading in the game demo, so I don't have an example to show just yet. The next Chickensoft package I'm working on will hopefully help reduce the workload of implementing versioned game save systems, so hang tight.
💉 Dependency Injection
Once you know about all the things you'll need, you have to figure out how to get it. We know our app is going to consist of visual components, state management mechanisms, repositories, and data clients.
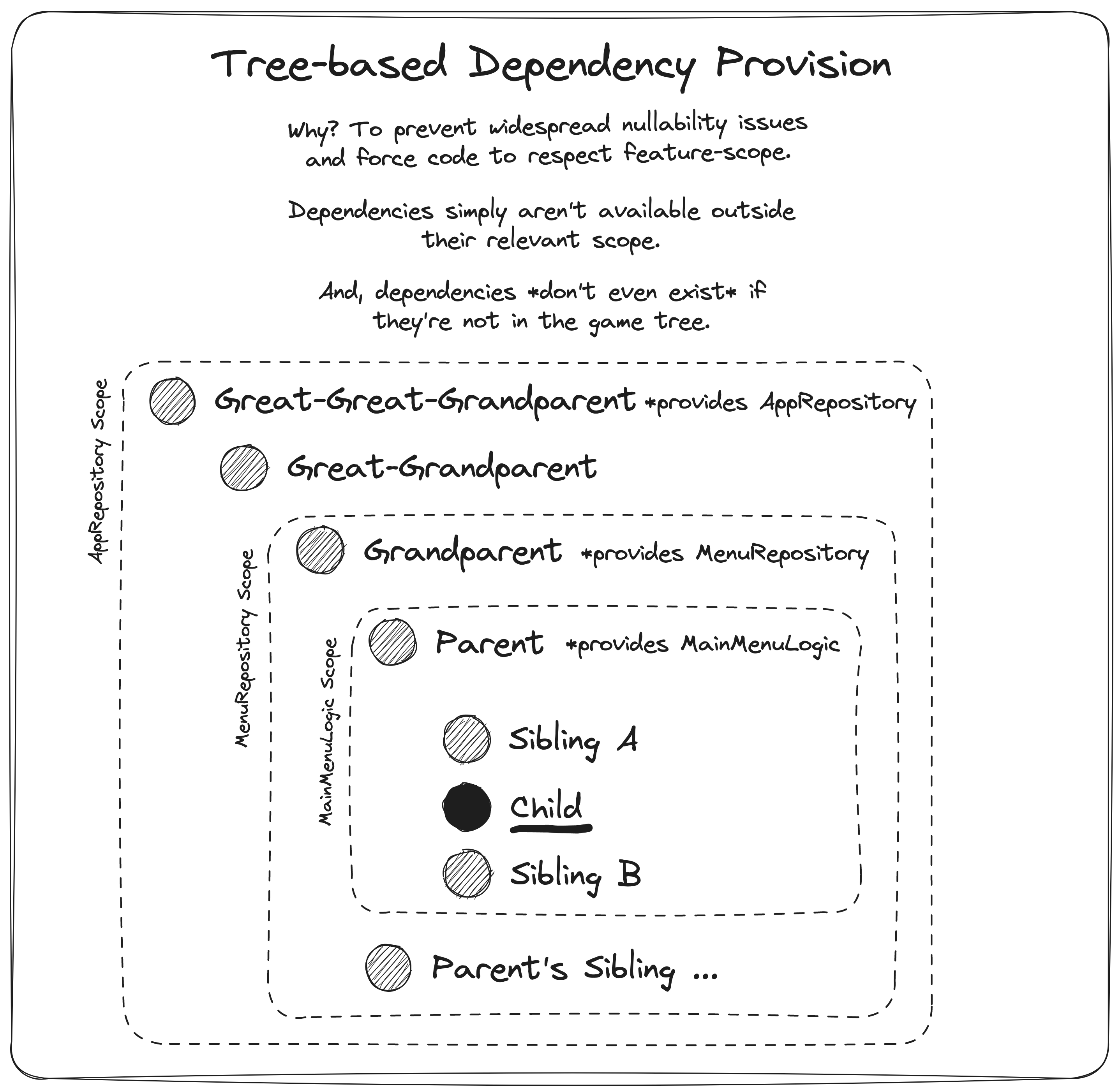
In the real world, references to objects will trickle downward through each layer of abstraction until they settle into the right place. We're following the "objects in one layer shouldn't know about any other objects except those in the layer directly below them" rule from layered architecture, but once again, the real world isn't quite so squeaky clean.
In reality, here's how it actually works.
A godot node script can provide a value to its descendants. In our game demo, the Player node script provides the its logic block, PlayerLogic, to its descendant nodes, allowing them to bind to its state machine.
To get this value for the first time, though, each descendant will need to search their ancestors to see if any of them provide the type of value they're looking for.
In all but the deepest trees, doing an ancestor walk is a very quick way to resolve a dependency provider. Deeper trees can re-provide the value to lower sections, reducing search distances.
There's another problem, though. In Godot, the deepest nodes are "readied" up before their ancestors. This means that the dependent nodes are asking their ancestor provider nodes for values that the providers haven't necessarily had a chance to initialize.
We solve this problem using AutoInject, which itself leverages the Introspection source generator. Under the hood, AutoInject temporarily subscribes to providers for the values it needs. Once the providers have indicated all their dependencies are good to go, AutoInject will make sure the dependent nodes have a chance to set themselves up. If providers immediately provide their values as soon as they're ready (and they should), all of this can happen in the same frame, making everything nice and deterministic.
To provide a value using AutoInject, our Player node simply needs to implement IProvide<T> for all of the value types it wants to provide.
[Meta(typeof(IAutoNode))]
public partial class Player : CharacterBody3D, IPlayer, IProvide<IPlayerLogic> {
public override void _Notification(int what) => this.Notify(what);
#region Provisions
IPlayerLogic IProvide<IPlayerLogic>.Value() => PlayerLogic;
#endregion Provisions
// ...
public void OnReady() {
PlayerLogic = new PlayerLogic(/* ... */);
Provide(); // Indicate the dependencies we provide are now available.
}
}
A descendant can just as easily access a dependency from an ancestor node by using the [Dependency] attribute on a property.
The PlayerModel node, which is a descendant of the Player node, binds to the player state machine and triggers visual animations based on the state machine's outputs.
[Meta(typeof(IAutoNode))]
public partial class PlayerModel : Node3D {
public override void _Notification(int what) => this.Notify(what);
#region Dependencies
[Dependency]
public IPlayerLogic PlayerLogic => DependOn<IPlayerLogic>();
#endregion Dependencies
public void OnResolved() {
PlayerBinding = PlayerLogic.Bind();
PlayerBinding
.Handle<PlayerLogic.Output.Animations.Idle>(
(output) => AnimationStateMachine.Travel("idle")
)
.Handle<PlayerLogic.Output.Animations.Move>(
(output) => AnimationStateMachine.Travel("move")
)
.Handle<PlayerLogic.Output.Animations.Jump>(
(output) => AnimationStateMachine.Travel("jump")
)
.Handle<PlayerLogic.Output.Animations.Fall>(
(output) => AnimationStateMachine.Travel("fall")
)
.Handle<PlayerLogic.Output.MoveSpeedChanged>(
(output) => AnimationTree.Set(
"parameters/main_animations/move/blend_position", output.Speed
)
);
}
// ...
}
😶🌫️ Simplified Dependencies
Using such a simple dependency system provides a number of advantages.
- Simple to reason about.
- Follows Godot's natural tree-based structure.
- Avoids nullability issues. Objects only exist when needed, where needed. Either the object and its dependents exist, or none of them exist. No more checking from your dependents to see if the thing you need is null or has null values.
- Declarative style of coding, making it clear what's responsible for what.
Behind the scenes, AutoInject takes care of looking up providers, caching, subscribing to providers while it waits for them to provide values, and invalidating the cache when re-entering the tree. All we have to do is say what we're providing or what we want, and make sure our descendants are placed beneath ancestors that give them the values they need.
In the game demo, you can just search for [Dependency] to see every value that's looked up from an ancestor node. The visual nodes in the demo make extensive use of AutoInject to lookup repositories. Once dependencies are resolved, the repositories are passed to the state machines for the nodes.
🧑🔬 Testing
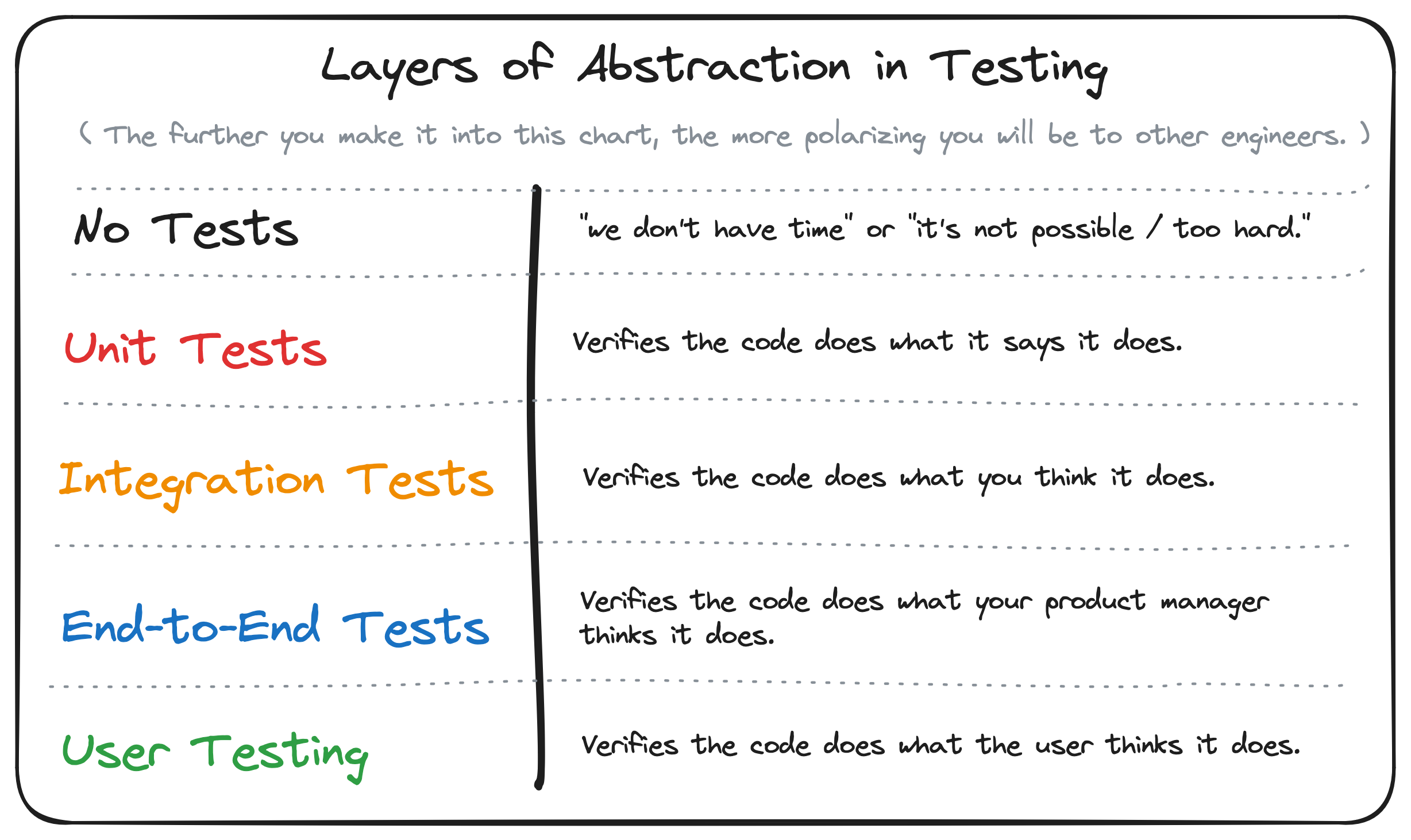
If a software architecture allows all of the application's individual "units" — i.e., network clients, repositories, states, and views — to be tested independently of each other, it's probably a decent architecture. After all, testing something in isolation is the definition of a "unit test".
In unit testing, a "unit" is the smallest possible unit of code that can be tested in isolation. This annoying, recursive definition is important, because the quality of the architecture can determine how big a unit is. In an ideal world, each unit would belong in one — and only one — layer of abstraction.
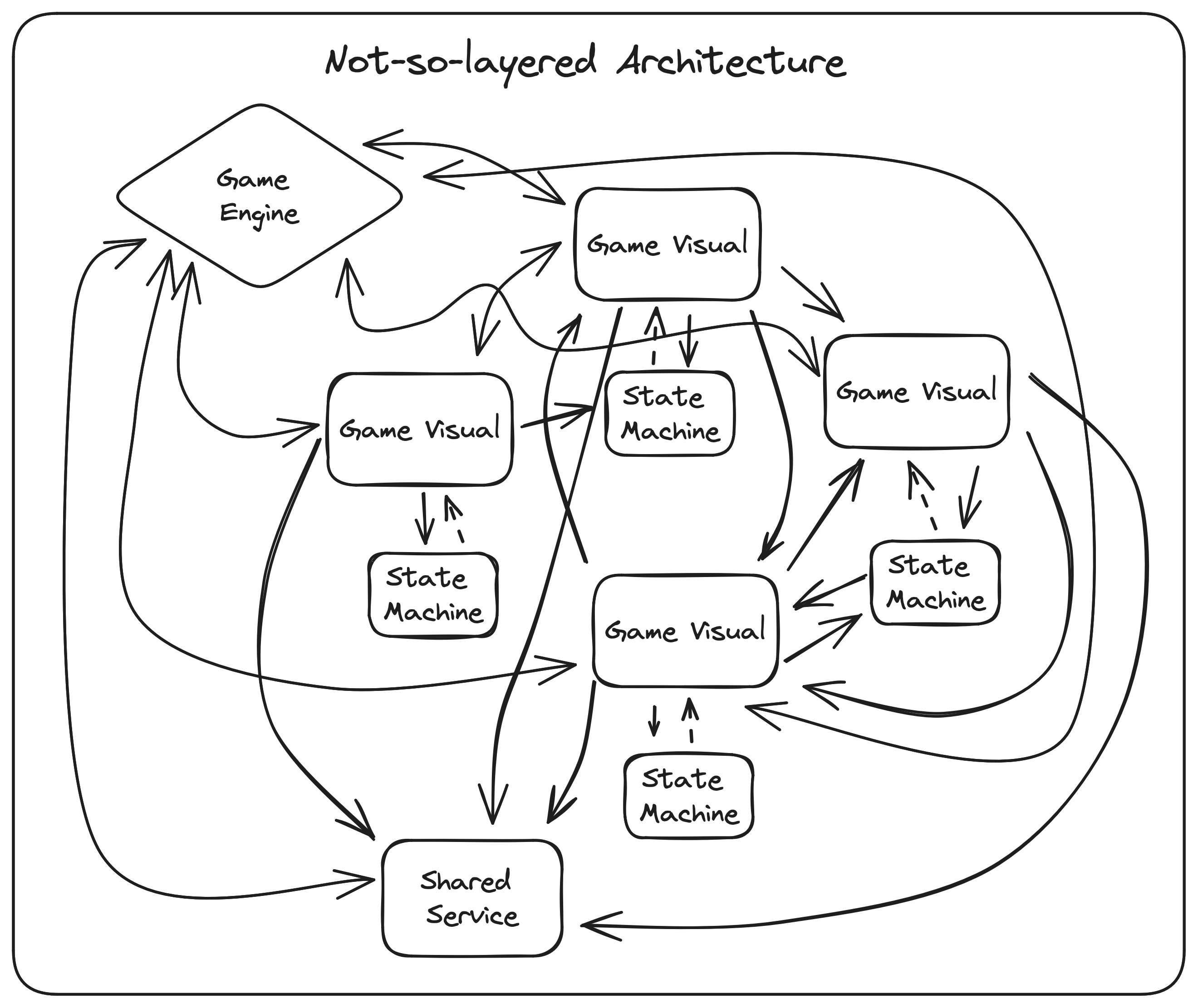
Historically, unit-testing visual components in game engines has been nearly impossible. Even Unity admits that a MonoBehavior can't really be unit-tested.
In Godot, things are a little better. You can easily spin up a new instance of a scene, add it to a test scene, and use GoDotTest with GodotTestDriver to call the scene script's methods and assert that it manipulates the engine environment as you expect, and then undo anything it changes.
Most people stop at this point, perfectly happy to be able to write tests for most things in their game. And that's fine, especially if you don't want to measure code coverage.
If you cannot quench your thirst for testing, and you find yourself wanting to measure code coverage accurately, the approach mentioned above won't quite work. You'll quickly realize that spinning up a scene means any of its child scenes get spun up, too. And if those child scenes have scripts, those get executed. That brings in a ton of other systems that you need to mock or swap in fake objects for, but there's no way to intercept the deserialization of the scene and swap everything out.
By now, your simple "unit" test has gone supernova, and is crossing so many layers of abstractions that your test has exploded into an integration test. As a result, your test ends up testing everything else in your game, and your code coverage becomes meaningless.
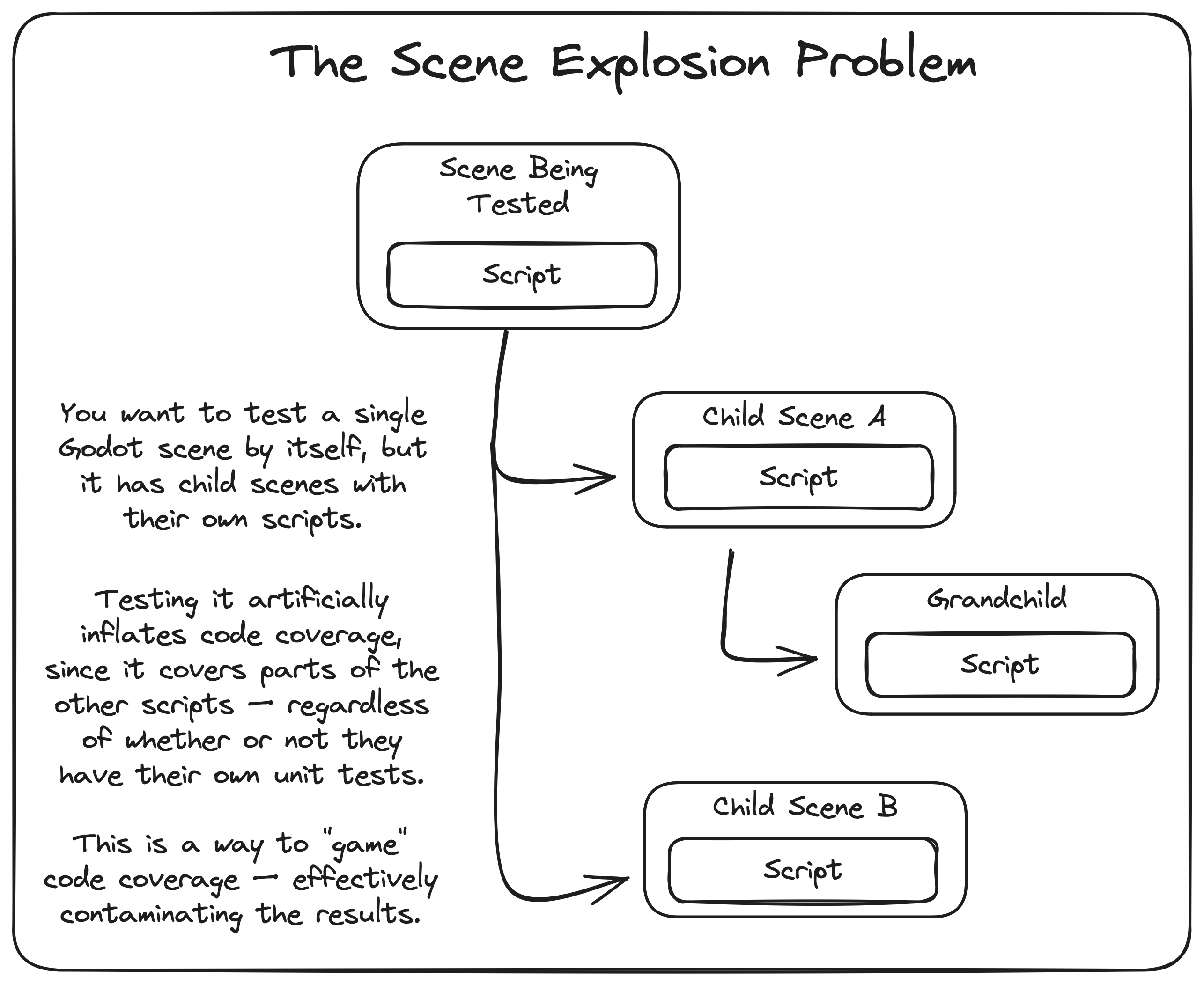
After all, code coverage is only accurate if you test each system in perfect isolation. Otherwise, you're contaminating the results and you won't be able to easily tell which systems you haven't tested yet.
I can hear you wondering "well, what's the point of unit testing, then? Is it even worth it to test such small 'units' of functionality?"
Yes, but not because we want to verify behavior. That's just an added bonus.
Wait, what? The point of unit testing isn't to verify behavior? Correct — at least, in my opinion.
🧪 Why Write Unit Tests At All?
I feel the same about unit tests as I do about high school teachers insisting we "show our work" in algebra class. It's a total chore, but it builds expertise and it's the right thing to do, even if you can just "solve it all in your head" (you never can when it comes to code).
Chores are just that. Necessary. We have to keep our houses clean or we end up with a bug infestation. Likewise, we have to keep our code clean or we end up with — wait. You get the idea.
If you, like me, dread cleaning your house, you should recall the age-old rule: if you have to do something you don't like, make it as easy as possible to do. Set yourself up for success. Listen to your favorite music while you clean the house and promise yourself you'll go out to dinner after.
So here's why I actually think unit tests are important:
- Unit tests are "showing your work." They ensure every line of code is executed at least once.
- Unit tests enforce consistency and ensure your architecture is followed. If you're not following the same architecture, it becomes harder to write tests. - Let's be honest: most tests start out as a copy/paste of some other tests, so you want to get this right up front.
- Unit tests are disposable. If you refactor something heavily, it's probably easier to just delete the tests and start over than it is to refactor the tests. Plus, you'll end up with better tests and it's often faster, anyways. If you're writing code decently well, this will be a non-issue.
- Unit tests act as living documentation. Your project wouldn't compile if they weren't up-to-date. If a developer needs to know how to use a particular piece of code, they can quickly look at the tests and get everything they need, because all of that code's capabilities will have tests.
- Unit tests verify the state and/or behavior of the test subject.
The fact that unit tests verify your code does what you say it does is just the icing on top. If code is strongly coupled, it becomes almost impossible to unit test. The mere existence of unit tests proves the code isn't terrible.
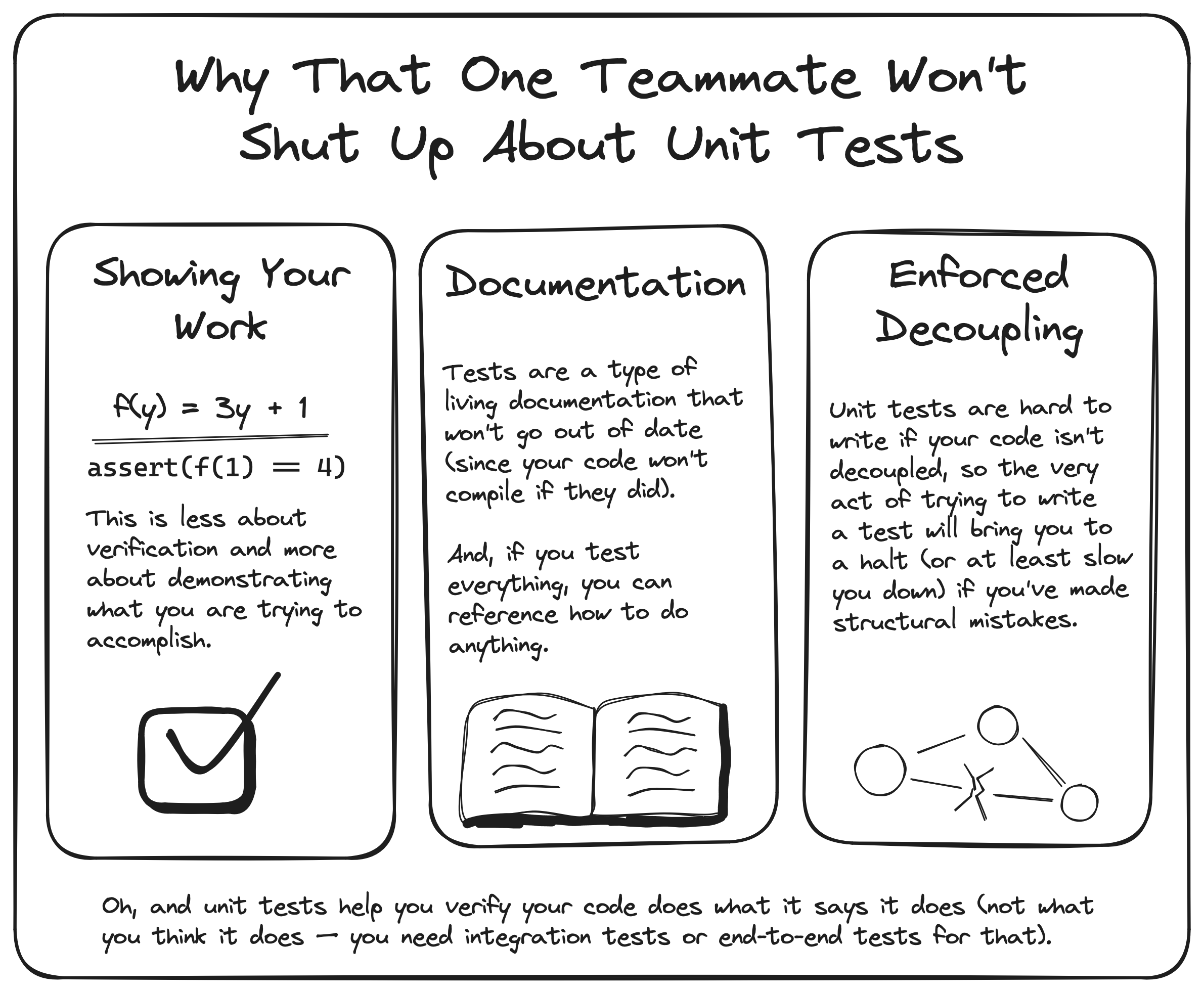
If unit tests feel repetitive, it's because they are. Depending on the test subject, you might end up testing a bit of behavior and state, which means that some of the tests can end up pretty tightly coupled. Obviously, with some practice or test utility abstractions, you can make them less coupled, but there tend to be plenty of tests that are basically just verifying the implementation of the test subject. And that's fine, because they're disposable. With today's AI-assisted coding, you'll be fine — I promise.
If you're just making a prototype of a game to get the gameplay right, you're not going to want to write many unit tests, if any. Unit testing tends to lock-in a lot of code, so don't do it until you're making the actual game.
An optimal architecture allows a game to achieve 100% code coverage through unit tests. There will always be situations where performance-critical code might be so tightly coupled that testing it in isolation is too difficult and a unit crosses more than one layer of abstraction. Fortunately, if everything else in your codebase is modularized enough to be tested in isolation, carving out a little blast radius where the rules are broken is perfectly allowable. It's one of those “you have to know the rules to break the rules” type of things.
Assuming you're convinced, let's talk about how it's actually done, now.
🔬 Unit Tests In Practice
To be able to test Godot scenes that incorporate other scenes, we need to be able make an instance of a scene without deserializing the actual scene file. Fortunately, Godot allows us to just new up any scene script we want — problem solved. Except, not quite. Once we add the script to the test scene to begin testing it, it will crash if it tries to find any children, since it won't have any. The child instances come from the .tscn file that we'd normally deserialize when loading a scene, but since we just created an instance of a script, there won't be any children.
That's fine. We can just add a little functionality to our script (using a mixin) that simulates a fake node tree and returns fake nodes based on the paths it expects. This works surprisingly well, except we can't return interfaces, making mocking impossible. The reason we can't return interfaces is because Godot nodes don't actually have any corresponding interfaces — they're just classes.
Since there’s no interfaces, we have to create an actual node for every child. And that gets really tedious really fast, resulting in a ton of test fixtures.
So, to get around this, I’ve created GodotNodeInterfaces, which generates interfaces and adapters for every type of Godot node. It also provides alternative methods for accessing child nodes as their adapted interface, and works with a fake scene tree system for testing.
I haven't done extensive profiling with GodotNodeInterfaces, since I was getting hundreds of frames per second while using it. I imagine there’s a slight performance impact in cases where the compiler can’t inline everything.
Because the alternative child access functions GodotNodeInterfaces provides return wrapped versions of real Godot nodes, there’s an allocation overhead. Fortunately, the allocation overhead can be mitigated by storing node references at the time your node script is created, getting all the allocations out of the way at once.
If you’re still worried about performance, though, take it from one of my personal heroes, Bob:
My experience, though, is that it’s easier to make a fun game fast than it is to make a fast game fun. One compromise is to keep the code flexible until the design settles down and then tear out some of the abstraction later to improve your performance. — Architecture, Performance, and Games
See? There’s always plenty of time to write bad code! Once your game becomes sickeningly clean, stable, and fun to play, you have my blessing to corrupt it for the sake of performance. After all, “all magic comes at a price,” or something like that.
💁 Testing Tips
If you haven't done much testing with C#, you'll probably want to familiarize yourself with the basics, including mocking.
In this last section, we'll demonstrate how the architecture we've outlined above allows us to test everything relatively easily.
🎨 Understanding Visual Testing
To test visual components, we have to reason very carefully about them. As mentioned previously, there's two ways to instantiate a Godot node for testing.
Instantiate the visual component's scene script directly. We avoid doing this in unit tests since it would pollute code coverage by executing more than one unit in a uni-test. For integration tests when we're not measuring code coverage, instantiating scenes directly works easily enough.
Create a new instance of a scene script, without deserializing its scene. This breaks child relationships once added to a scene tree, since those children don't exist since we didn't deserialize a scene file. We can get around this by using a fake scene tree system, which is what GodotNodeInterfaces provides.
We will always use approach #2.
Once we have an instance of a node to test, there's two ways to test it.
We can add the node to the test scene tree, which allows it to manipulate the game engine environment and take up space in the world. For many nodes, we have to actually add them to the scene tree during testing to be able to verify their interactions with the engine.
Alternatively, we can just call methods on the node without adding them to the scene tree. This works if nothing in the methods manipulates the scene tree or other properties of the node that require it to be in the tree. For many nodes, we can get away with this approach, since it's a bit simpler.
👷 Setting Up Testing
We'll be using GoDotTest as our test runner. GoDotTest guarantees a few invariants for us that help us run tests deterministically.
- Tests are always executed one at a time, in the order they appear in the code for a particular test class.
SetupandCleanupmethods can be called before and after each test, andSetupAllandCleanupAllmethods can be called before and after running a test suite (i.e., a test class).- Tests are able to be placed on the test scene.
- Tests can be run from the command-line, for CI/CD purposes.
- Tests are never run in parallel.
- Tests and their setup methods can be asynchronous, or not.
🧬 Two-Phase Initialization
We frequently need to separate our script's initialization into two phases: one phase for creating the values that belong to that script, such as its dependencies, state machines, and bindings, and the second for using those dependencies or bindings. If we don't separate the initialization from the usage, we won't have a way to inject mock values during a unit test since the values would be created and immediately used afterwards.
In practice, here's what splitting our initialization into two-phases looks like.
[Meta(typeof(IAutoNode))]
public partial class InGameUI : Control, IInGameUI {
public override void _Notification(int what) => this.Notify(what);
#region Dependencies
[Dependency]
public IAppRepo AppRepo => DependOn<IAppRepo>();
#endregion Dependencies
#region Nodes
[Node]
public ILabel CoinsLabel { get; set; } = default!;
#endregion Nodes
#region State
public IInGameUILogic InGameUILogic { get; set; } = default!;
public InGameUILogic.IBinding InGameUIBinding { get; set; } = default!;
#endregion State
public void Setup() {
InGameUILogic = new InGameUILogic(this, AppRepo);
}
public void OnResolved() {
InGameUIBinding = InGameUILogic.Bind();
InGameUIBinding
.Handle<InGameUILogic.Output.NumCoinsCollectedChanged>(
(output) => SetCoinsLabel(
output.NumCoinsCollected, AppRepo.NumCoinsAtStart.Value
)
)
.Handle<InGameUILogic.Output.NumCoinsAtStartChanged>(
(output) => SetCoinsLabel(
AppRepo.NumCoinsCollected.Value, output.NumCoinsAtStart
)
);
InGameUILogic.Start();
}
Once again, we're looking at the InGameUI view that displays the number of coins the user has collected while in-game. Notice the separate methods, Setup() and OnResolved(). The first method creates the InGameUILogic state machine, while the second binds to the state machine's outputs and starts the state machine.
Since the script above uses AutoInject to resolve dependencies, we can leverage a lesser-known feature of AutoInject to help with this initialization process. AutoInject normally calls the OnResolved() method on your script once all the providers it found for your script's dependencies indicate they've provided their values, but there's more to it than that.
If you have a Setup() method on your script, that method will be called after dependencies are resolved, but right before OnResolved() is called — if, and only if — your script's IsTesting property is set to false. The IsTesting property isn't shown, though — it's tucked away in a generated file.
By utilizing two-phase initialization, we are able to test our game component easily within the scene tree.
I won't show full tests here, but you can check out the tests for the Player node. It takes advantage of the two-phase initialization by preventing the Player's Setup() method from ever being invoked when running in the actual test scene, ensuring our mocked values get injected instead.
🌲 Faking the Scene Tree
Each scene should have only one script on its root node.
If you find yourself needing to add a script to a non-root node in a Godot scene, don’t. Instead, save the node branch as its own scene before adding a script to it.
Likewise, if you you find yourself writing a Godot node script that manipulates its grandchildren, you may run into difficulty testing the script as a unit-test with a fake node tree. For best results, add a script to the child and ask it to manipulate its own children from your script. The general rule of thumb is "no script should manipulate nodes deeper than its children."
Ensuring each scene only has one script on its root node allows you to make use of the fake scene tree system provided by GodotNodeInterfaces to easily test your scene. By referencing nodes as interfaces and automatically hooking them up with the IAutoConnect mixin, we can easily test our scene in isolation without spinning up the entire subtree.
In the example below, taken from the game demo's unit tests for the spinning gold coins, we setup our tests by creating mock versions of the values the coin needs and then call the FakeNodeTree to instruct our coin to use the mock objects for nodes at the provided paths instead of trying to connect to real children nodes.
[Setup]
public void Setup() {
_appRepo = new Mock<IAppRepo>();
_animPlayer = new Mock<IAnimationPlayer>();
_coinModel = new Mock<INode3D>();
_logic = new Mock<ICoinLogic>();
_binding = CoinLogic.CreateFakeBinding();
_logic.Setup(logic => logic.Bind()).Returns(_binding);
_coin = new Coin {
IsTesting = true,
AnimationPlayer = _animPlayer.Object,
CoinModel = _coinModel.Object,
CoinLogic = _logic.Object,
CoinBinding = _binding
};
_coin.FakeDependency(_appRepo.Object);
_coin.FakeNodeTree(new() {
["%AnimationPlayer"] = _animPlayer.Object,
["%CoinModel"] = _coinModel.Object
});
}
🥸 Mocking Dependencies Provided with AutoInject
In the example above, we also used the FakeDependency method generated with AutoInject. Faking a dependency prevents the dependent node from searching the tree for providers — which wouldn't be present in a test scenario where you're just testing a script by itself. Instead, the dependent node we're testing will just use the provided value when it looks up a dependency of that type, allowing us to easily mock dependencies.
🗂 File Structure and Feature-Based Architecture
Files should be organized in a way that benefits the artists and developers contributing to the codebase. Allow me to suggest feature-based organization here.
In feature-based organization, files are organized by feature, with any files that get shared between features in some sort of shared directory, typically called something like common.
In the game demo, we define features pretty simply. The player runs around collecting coins, jumping on mushrooms, and interacting with a physical environment. So, a mushroom is a feature, so is a coin, etc. You can define features however you want, but you probably want to check out the section "Thinking in Tokens" in Chapter 17 (page 482) of Game Architecture and Design: A New Edition by Rollings and Morris.
In feature-based architecture, you really want to avoid strongly coupling your features together. If you can keep them loosely coupled, you can add and remove them with ease.
Take a look at how the files are implemented for the Coin feature:
├── src
│ ├── coin
│ │ ├── Coin.cs
│ │ ├── Coin.tscn
│ │ ├── CollectorDetector.tscn
│ │ ├── audio
│ │ │ ├── coin_collected.mp3
│ │ │ └── coin_collected.mp3.import
│ │ ├── state
│ │ │ ├── CoinLogic.Input.cs
│ │ │ ├── CoinLogic.Output.cs
│ │ │ ├── CoinLogic.State.cs
│ │ │ ├── CoinLogic.cs
│ │ │ ├── CoinLogic.g.puml
│ │ │ └── states
│ │ │ ├── CoinLogic.State.Collecting.cs
│ │ │ └── CoinLogic.State.Idle.cs
│ │ └── visuals
│ │ ├── coin_model.glb
│ │ ├── coin_model.glb.import
│ │ ├── coin_normal.tres
│ │ ├── coin_roughness.tres
│ │ ├── coin_texture.tres
│ │ └── teleport_3d.gdshader
Everything the coin needs is located inside the coin folder. Even the states for the state machine are located in the state/states subfolder. All the other features are organized in the same way, too, making it easy for a developer to jump in and fix something, even if she hasn't been working on that feature. Artists can also quickly intuit where they might need to drop some updated visuals, too.
I often see people suggest to keep separate folders for each type of file, like scripts, scenes, textures, etc. My little brain finds this organizational pattern difficult since related files are split across multiple places and it makes it harder to remember to go and rename the corresponding files in top-level directories elsewhere whenever you decide to rename something. You also have to know how to identify all the related files, too, which becomes a memory exercise in and of itself.
🪢 Preventing Strong Coupling in Features
To keep my features from being strongly coupled to each other, I made them interact with each other via interfaces. For example, the coin can be collected by anything that implements ICoinCollector. The coin doesn't care what it is, it just knows that it can be collected by anything that implements that interface. In the game, it's just the player.
To facilitate this, I simply created a folder in my src directory that contained interfaces used across features. I could have put these in a common directory, but I decided to have a traits directory for this sort of thing.
├── src
│ ├── traits
│ │ ├── ICoinCollector.cs
│ │ ├── IKillable.cs
│ │ └── IPushEnabled.cs
No doubt, you can find further organizational patterns that improve on this. When you do, please pop into our Discord and share them with me ^-^.
🏛 File Structure for Tests
The unit tests for everything in the game demo are 1:1 mirror of everything in the source directory that needs tests, with the added Test suffix added to each file.
└── test
└── src
├── coin
│ ├── CoinTest.cs
│ └── state
│ ├── CoinLogicTest.cs
│ └── states
│ ├── CoinLogic.State.CollectingTest.cs
│ └── CoinLogic.State.IdleTest.cs
🥰 Conclusion
Thank you for reading my (excessively long) article on game architecture. There's no way I could dive into everything into as much detail as I wanted, so if you have questions, please feel free to reach out to me. If you find ways of working that are easier, better, and more enjoyable, please don't keep them to yourself. I'd love to assimilate your knowledge!